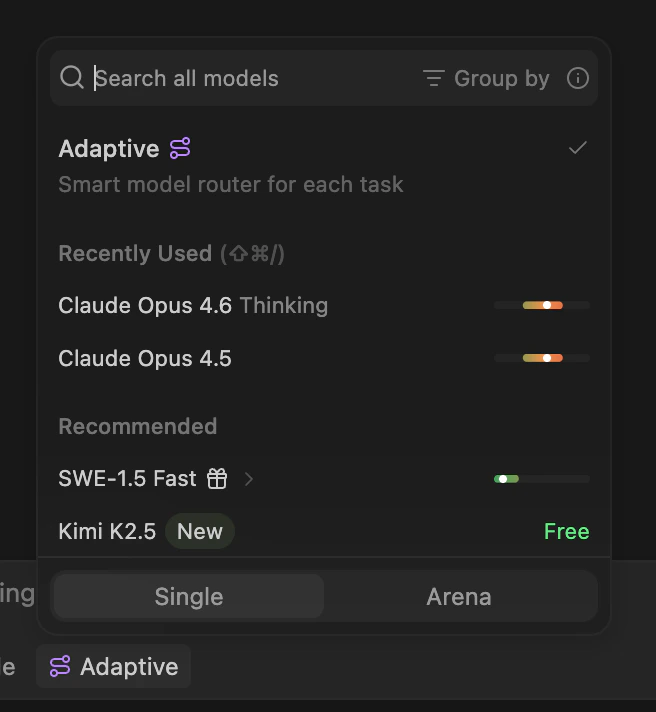
Adaptive を利用するには、Cascade の入力ボックスの下にあるモデルピッカーを開き、リストの最上部にある Adaptive を選択します。選択すると、以降の会話内のすべてのメッセージで Adaptive が利用されます。
スマートなモデルルーティングを有効にするには、モデルピッカーで Adaptive を選択します。
Adaptive は、ほとんどのユーザーにとって最適なデフォルト設定です。
- Devin Desktop: Settings > Devin Desktop > Models に移動し、Adaptive モデルルーター をオンにします。
- Windsurf: Team Settings > Models に移動し、Adaptive モデルルーター をオンにします。
Adaptive の料金は、ご利用の課金プランによって異なります。
Adaptive では、各リクエストでどの基盤モデルが選択されても、トークンあたりの固定料金で利用枠が消費されます。現在、Adaptive の利用枠消費量と超過分には、導入記念のプロモーション料金が適用されています (2026 年 7 月 7 日まで) 。これらの料金は、含まれる利用枠を超えた追加使用量にも適用されます。Adaptive はより単純なタスクを軽量なモデルに振り分けるため、通常、すべてのリクエストで frontier モデルを手動で選択する場合よりも、全体のトークン消費量が少なくなります。そのため、ほとんどのユーザーにとって最も費用対効果の高い選択肢です。 Cognition Platform をご利用のお客様では、Adaptive の使用量は ACU (Agent Compute Units) で計測されます。ACU消費量は、使用されたトークン数と、各リクエストでルーターが選択したモデルに応じて増減します。
クレジットベースの課金をご利用の Enterprise のお客様では、Adaptive にはトークン数に応じて変動するクレジット料金が適用されます。各リクエストでは、実際に使用されたトークン数と、そのリクエストに対して Adaptive が選択したモデルに基づいて、クレジットレートに応じたクレジットが消費されます。つまり、低コストのモデルほど 1 リクエストあたりのクレジット消費量は少なくなり、Adaptive のルーティングは自然に費用効率の高い選択を優先するため、常に高価格帯のモデルを選択する場合と比べて、クレジットプールをより長く使えます。
- プロンプトは具体的にしてください。 明確で要点を押さえた指示にすると、Adaptiveが適切なモデルに振り分けやすくなり、不要なトークン使用量も抑えられます。
- プロンプトキャッシュを活用してください。 conversation 内で複数ターンにわたって同じモデルを使い続けるとキャッシュが有効になり、入力トークンのコストを大幅に削減できます。Adaptive はルーティング時にこれも考慮します。
- デフォルトでは Adaptive を利用してください。 ほとんどのワークフローでは、Adaptive が最適な出発点です。特別な理由がある場合にのみ、特定のモデルに切り替えてください。たとえば、複雑なタスクで特定のモデルの推論能力が必要な場合です。